さて、日ごろひそかに注目している方の一人にSFC(慶應義塾大学 湘南・藤沢キャンパス )の藤田将洋
さんがいらっしゃいます。
そちらのページでは、サブサーフェス散乱やシルエットエッジレンダリングのような興味深い研究が公開されています。
その中でも特に興味を引いた研究はレリーフテクスチャに関しての研究でした。
レリーフテクスチャはCgのコーディングコンテストの3回目で応募されていた方がいらっしゃったり、
とても興味深いネタだと思います。
今回は、DirectX9のパワーを利用して、逆ワーピング法でレリーフテクスチャを実装してみたいと思います。
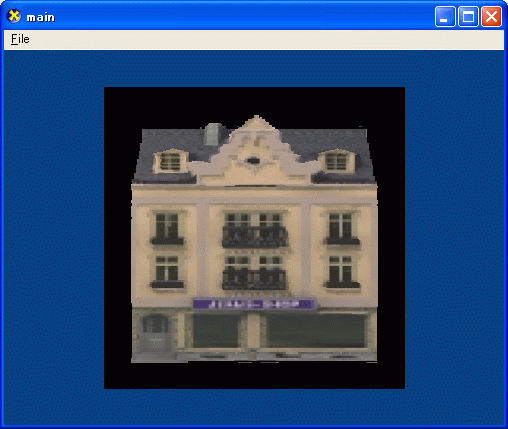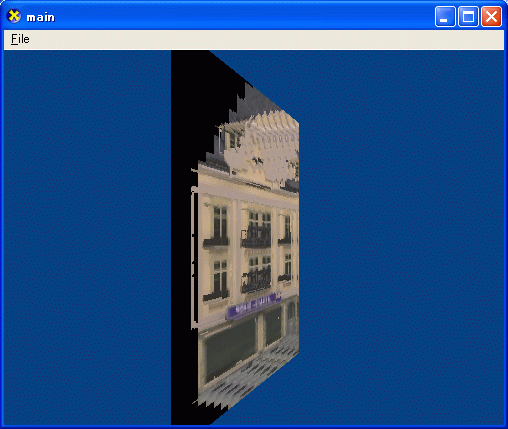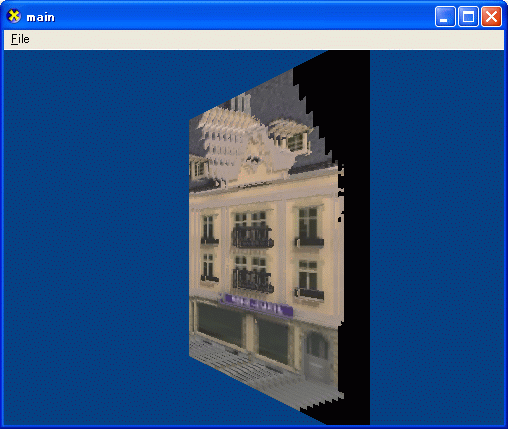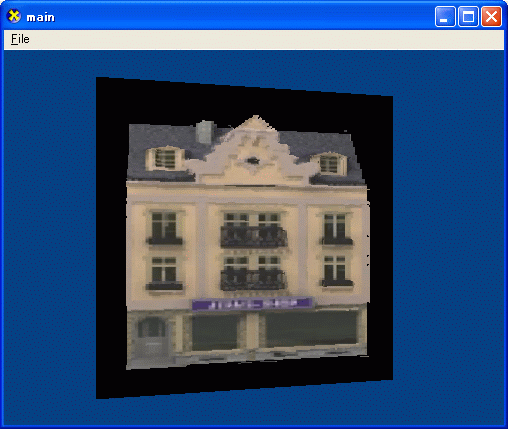
ちなみに、上の画像はポリゴンを1枚レンダリングしただけです。
まぁ、いつものように適当にファイルが入っています。
APP WIZARD から出力されるフレームワークのファイルは紹介を省かせていただきます。
| hlsl.fx | シェーダの入ったエフェクトファイル |
| main.h | アプリケーションのヘッダ |
| main.cpp | アプリケーションのソース |
あと、実行ファイル及び、プロジェクトファイルが入っています。
さらに、メッシュからリリーフテクスチャのための画像を作るためのプログラムも作ってみました。
メッシュを読み込んで色、深度、法線ベクトルを表示します。
左右のカーソルで見る方向を変えることができます。
手を抜いたので、保存する方法がありませんので、
「Print Screen」ないし、画面キャプチャで気に入った画像を取り出してください。最低限の機能ですが、現在表示されているテクスチャを保存する機能をつけました。また、中心座標をあわせるように調整しました(2003 Jan. 15日追加)。
MRTを3枚使っているので、動くかどうか保証できません。ご注意ください
(駄目だったら報告をお願いします)。
レリーフテクスチャとは、深度マップを利用して比較的高速に立体的なオブジェクトをレンダリングする方法です。
ポリゴンの各ピクセルに関して、深度マップからテクスチャ座標がどれくらいずれるのか算出して、
ずらしたテクスチャ座標によって、シーンをレンダリングします。
すれたテクスチャ座標さえ求めることができれば、デカールのマップや法線マップから思うがままにレンダリングできることはすぐに分かると思います。
レリーフテクスチャは、バンプマップとディスプレースメントマップのちょうど中間的な手法で、
平面的なポリゴンの板をレンダリングしますが、幾何学的に見た目が正しいレンダリング結果を出力します。
今回使用する方法は、逆ワーピング法と呼ばれる方法で、レンダリングするポリゴンの各ピクセルに関して、
深度情報を考慮に入れたレンダリングするテクスチャ座標を求めて、
そのテクスチャ座標で各種テクスチャをサンプリングします。
より具体的には、テクスチャを何枚ものレイヤーに重ねた状況を考えます。
そのレイヤー群に関して、視点からレイを飛ばして、交差した各ポイントに関して、
深度テクスチャの値とレイヤーの深度を比較して、レイが交差するか調べ、
交差したUV値をデカールテクスチャなどのテクスチャ座標としてサンプリングします。
これ以外の方法としては、前方ワーピング法と呼ばれる方法があります。 前方ワーピング法では、深度テクスチャの各テクセルに関して、 3次元空間に置かれたポリゴンの位置情報と深度からレンダリングターゲットの位置座標を調べて、レンダリングします。
前方ワーピング法は、正確な形をレンダリングすることができますが、
テクスチャ座標からレンダリング先を求めなくてはならないので、
現在のプログラマブルシェーダのアーキテクチャでは、直接的なハードウェアの支援は難しいものとなっています。
一方、逆ワーピング法は、比較的ハードウェアによる高速化がしやすくはありますが、
ポリゴンからはみ出した部分は掛けてしまうので、取り扱いに注意が必要です。
実は、はみ出した部分に関する問題の解決法はよく知られていて、 レリーフテクスチャで6方向を囲んだ立方体のオブジェクトを作って、 それら全てのテクスチャに対してレリーフテクスチャのマッピングをすれば、 欠けることなくレンダリングできます。
レリーフテクスチャは、最前面の深度情報だけを使ってレンダリングするので、
まさにレリーフのような板を掘り込んだ画像しか作ることができません。
今回の方法では、テーポットのような丸まったオブジェクトをレンダリングすると、
手前の部分の曲面は再現できますが、
奥に回りこんだ部分は再現できずに、奥に伸びた画像になってしまいます。
逆に、前方ワーピング法の場合には、ぺらぺらした板のようにレンダリングされるので、 斜めから見ると厚みが無い殻のオブジェクトに見えてしまいます。
今回は、シェーダを設定して、ポリゴンの板を表示するだけなので、
シェーダの説明だけにさせてもらいます。
ちなみに、ポリゴンの板のローカル座標は
のように、z=0平面上においています。テクスチャ座標は、今回、一回り大きめにとりました。 こうしておくと、傾いたときに切り落とされる部分が少なくなります。
頂点シェーダでは、いつもどおり射影空間の座標とテクスチャを出力すると共に、 特殊な視線ベクトルを出力します。
hlsl.fx
0049: // -------------------------------------------------------------
0050: // 頂点シェーダプログラム
0051: // -------------------------------------------------------------
0052: VS_OUTPUT VS (
0053: float4 Pos : POSITION // モデルの頂点
0054: , float4 Normal : NORMAL
0055: , float4 Tex : TEXCOORD0
0056: ){
0057: VS_OUTPUT Out = (VS_OUTPUT)0; // 出力データ
0058:
0059: // 位置座標
0060: Out.Pos = mul( Pos, mWVP );
0061:
0062: // テクスチャ座標
0063: Out.Tex = Tex;
0064:
0065: // 視線ベクトル
0066: Out.Eye = vEyePos - Pos;
0067: Out.Eye *= 0.2f/Out.Eye.z;
0068: Out.Eye.y = -Out.Eye.y;
0069:
0073: return Out;
0074: }
今回の視線ベクトルは、いつもの視点へのベクトルを0.2倍して、z成分で割っています。
つまり、z成分が0.2の視線方向へのベクトルになっています。
この後、テクスチャのレイヤーを重ねた空間を考えて、
それらのレイヤーと視線ベクトルの交点を検索するのですが、
この視線ベクトルは、手前のレイヤーから、奥のレイヤーまでの視線ベクトル方向の変位ベクトルになります。
最後にy座標を-1しているのは、視線ベクトルを飛ばす空間を射影空間でなくて、
(奥行きを仮想的にもった)テクスチャ座標の空間で行なうので、
射影空間とテクスチャ座標系の間で向きが違うy軸をひっくり返しておきます。
ちなみに、0.2fという視線ベクトルに掛けた値は適当です。
このスケールの値は、レリーフの厚みになります。
前述したツールで出力する場合には、テクスチャの幅や高さのワールド座標系での大きさを深度の0~1に落とし込んでいるので、
視線ベクトルは、テクスチャ座標系でもワールド座標系と同じ傾きで進むと適切なレンダリング結果が得られます。
すなわち、スケールの値を1.0fにすると、正しい結果が得られます。
例えば、球の深度や法線マップを使ってレンダリングすると、スケールの値が0.2の時には、
の、斜めから見たときにゆがんだ座標が得られますが、 スケールの値を1.0fに書き換えてレンダリングすると、
のレンダリング画像が得られます。
レリーフテクスチャでは、最前面の深度情報しか持っていないので、
球をレンダリングしたときには、奥行き方向には伸びた、
「カプセル状」の結果が得られることになります。
注目するのはカプセルの手前の部分で、この部分が球に見えることが、
正しいスケールを与えていることの検証になります。
但し、今回は、奥行き方向に9回のサンプリングしかできなかったので、
奥に伸ばすとサンプリングしたレイヤーが見えてしまいます。
この、サンプリング数が少ない問題は、次の世代のGPUを待つという解決方法か、
レイヤーの位置をずらした画像を、深度情報とともに複数回作成して、
作成したテクスチャをさらに深度比較しながら合成する方法で解決できます。
さて、ピクセルシェーダですが、同じ関数をコピー&ペーストで実行する荒業を使っています。
uv は、テクスチャ座標系を検索する座標値になります。
最初は元のテクスチャ座標を検索して、その後は視線ベクトル方向に少しずつずらして、深度を検索します。
深度テクスチャは「TexSamp」です。サンプリングしたテクスチャの値と、現在調べているレイヤーの深度値を比較して、
テクスチャの深度値がレイヤーの深度値「d」よりも前なら(色が明るいなら)、
視線ベクトルは現在のUV値の点と交差しているので、
最終的に色をサンプリングするUV値に指定します。
ちなみに、視線ベクトルは、何度もレイヤーと交差する可能性がありますが、
一番最初に交差したUV値が一番前面に見えるUV値なので、
既に衝突したか判定するためのフラグ「ok」を設けて、一度交差したら、
以降はUV値を上書きしないように設定しています。
最初、奥から手前にサンプリングして行けば、「OK」はいらないと思ったのですが、
実際にプログラムしてみたら、命令数が増えてしまったので、今の形にしています。
ちなみに、プログラムの上限はピクセルシェーダの命令数になります。
ps.2.0+ではより多くの命令がつかえるので、さらに多くのレイヤーを使って分解能を高くできるでしょう。
最後に求めたUV値で色テクスチャを読み込んで表示します。
何所にも衝突しなかったピクセルはアルファ成分に0を代入して透明にして表示しています。
今回は簡単にテクスチャの色を出力しましたが、とりあえずUV値を色として出力しておいて、
2パス目で色々な加工をする手もありだと思います。
hlsh.fx
0075: // -------------------------------------------------------------
0076: // ピクセルシェーダプログラム
0077: // -------------------------------------------------------------
0078: float4 PS( VS_OUTPUT In ) : COLOR
0079: {
0080: float4 O = (float4)0;
0081:
0082: float4 col;
0083: float4 num = 9.0f;
0084: float2 dt = (1.0f/(num-1))*(In.Eye.xyz);
0085: float dd = 1.0/num;
0086: float d = 1.0001 - dd;
0087: float2 uv = In.Tex.xy;
0088: float2 st = 0;
0089: bool ok = false;
0090:
0091: col = tex2D( TexSamp, uv ); // 1
0092: st = (d<col.x && !ok) ? uv : st;
0093: ok = (d<col.x) ? true : ok;
0094: uv += dt.xy;
0095: d -= dd;
0096:
0097: col = tex2D( TexSamp, uv ); // 2
0098: st = (d<col.x && !ok) ? uv : st;
0099: ok = (d<col.x) ? true : ok;
0100: uv += dt.xy;
0101: d -= dd;
0102:
0103: col = tex2D( TexSamp, uv ); // 3
0104: st = (d<col.x && !ok) ? uv : st;
0105: ok = (d<col.x) ? true : ok;
0106: uv += dt.xy;
0107: d -= dd;
0108:
0109: col = tex2D( TexSamp, uv ); // 4
0110: st = (d<col.x && !ok) ? uv : st;
0111: ok = (d<col.x) ? true : ok;
0112: uv += dt.xy;
0113: d -= dd;
0114:
0115: col = tex2D( TexSamp, uv ); // 5
0116: st = (d<col.x && !ok) ? uv : st;
0117: ok = (d<col.x) ? true : ok;
0118: uv += dt.xy;
0119: d -= dd;
0120:
0121: col = tex2D( TexSamp, uv ); // 6
0122: st = (d<col.x && !ok) ? uv : st;
0123: ok = (d<col.x) ? true : ok;
0124: uv += dt.xy;
0125: d -= dd;
0126:
0127: col = tex2D( TexSamp, uv ); // 7
0128: st = (d<col.x && !ok) ? uv : st;
0129: ok = (d<col.x) ? true : ok;
0130: uv += dt.xy;
0131: d -= dd;
0132:
0133: col = tex2D( TexSamp, uv ); // 8
0134: st = (d<col.x && !ok) ? uv : st;
0135: ok = (d<col.x) ? true : ok;
0136: uv += dt.xy;
0137: d -= dd;
0138:
0139: col = tex2D( TexSamp, uv ); // 9
0140: st = (d<col.x && !ok) ? uv : st;
0141: ok = (d<col.x) ? true : ok;
0142:
0143: O = (ok)?tex2D( ColorSamp, st):0.0f;
0144:
0145: return O;
0146: }
ps.2.xを使えば、より精度の高いレンダリングが可能なはずです。
(ps.2.sw のソフトウェア実行で)分解能をテクスチャの分解能と同じ256段階で実行するプログラムは、次のようになります。
hlsh.fx(ps_2_sw)
0075: // -------------------------------------------------------------
0076: // ピクセルシェーダプログラム
0077: // -------------------------------------------------------------
0078: float4 PS( VS_OUTPUT In ) : COLOR
0079: {
0080: float4 O = (float4)0;
0081:
0082: float4 col;
0083: float4 num = 256.0f;
0084: float2 dt = (1.0f/(num-1))*(In.Eye.xyz);
0085: float dd = 1.0/num;
0086: float d = 1.0000001 - dd;
0087: float2 uv = In.Tex.xy;
0088: float2 st = 0;
0089: bool ok = false;
0090: float i;
0091:
0092: for ( i = 0; i < 1; i += 1.0f/num ) {
0093: col = tex2D( TexSamp, uv );
0094: st = (d<col.x && !ok) ? uv : st;
0095: ok = (d<col.x) ? true : ok;
0096: uv += dt.xy;
0097: d -= dd;
0098: }
0099:
0100: O = (ok)?tex2D( ColorSamp, st):0.0f;
0101:
0102: return O;
0103: }
このプログラムは、上のほうにある画像のティーポットのレンダリングに使っています。
6面体を使うと欠けることなくレンダリングできると書きましたが、
実際に実行してみないと軽んじられるので(ほんとか?)、
プログラムを組んでみました。
前出したツールで作った深度マップと法線マップとデカールマップを6面体に張り合わせてそれぞれリリーフテクスチャマッピングを施しました。
照明計算はランバート拡散です。
下のファイルが6面使うレリーフテクスチャマッピングのサンプルソースです。
| hlsl.fx | シェーダの入ったエフェクトファイル |
| main.h | アプリケーションのヘッダ |
| main.cpp | アプリケーションのソース |
どのくらい上の画像がすごいか見るために、 元になった深度マップをそのまま貼り付けた6面体を見てみましょう。
ほんとの箱です。
これがあたかも立体に見えるのですからすごいものです。
まぁ、よく見るとモデルに穴が開いているので、その部分の点が見えますが、
それがあっても結構まともに見えています。
ただし、上の画像はいい角度を選んで撮影したもので、
すべての向きでこのようにきれいに見えるわけではありません。
上ですでに述べていますが、原理的には、直方体しか厳密に再現できません。
出っ張りがあるモデルは、その部分の(表示している面の法線に対して)後ろの部分が
埋められてしまいます。
このモデルの場合には、上から見ると髪の毛が出っ張っているために顔がなくなってしまいます。
それ以外にもトラのモデルを使えば、足の間が埋まってしまったりします。
やっぱり遠くから見てごまかすときにしか使えなさそうです。
あと、上の画像はどれも256枚のレイヤーを使っていますが、
今回zipファイルに保存したソースは10枚のレイヤーを使ったps.2.0バージョンです(プログラム自体は存在しているので、fxファイルの「#if 0」を「#if 1」に書き換えればすぐに256枚のレイヤーで表示できます。あっ、REFで実行するのを忘れずにね)。
10枚のレイヤーを使った時には次のようになります。
やっぱり見れたものではないですね。
50枚以上のレイヤーは欲しいところです。
ちなみにプログラムは次のアセンブラになります。
hlsh.fx
0145: PIXELSHADER PS = asm
0146: {
0147: ps_2_0
0148:
0149: // c0:ライトベクトル
0150: def c1, 2.0, 1.0, 0.0, 0.000001
0151: def c2, 0.1, 5, 100000, 99999// 1/num, 5, 100000 100000-1
0152:
0153: dcl t0.xy // Depth
0154: dcl t1.xy // Eye
0155: dcl_2d s0 // Depth
0156: dcl_2d s1 // Color
0157: dcl_2d s2 // Normal
0158:
0159: mul r11.xy, t1, -c2.x // r0: dt = (-1.0f/num))*In.Eye;
0160: mov r11.z, c2.x
0161: mov r10.xy, c2.z // r10:st = 100000
0162: mov r0.xy, t0
0163: mov r0.z, c1.w
0164: add r2.xyz, r11, r0
0165: add r4.xyz, r11, r2
0166: add r6.xyz, r11, r4
0167: add r8.xyz, r11, r6
0168:
0169: texld r1, r0, s0
0170: texld r3, r2, s0
0171: texld r5, r4, s0
0172: texld r7, r6, s0
0173: texld r9, r8, s0
0174:
0175: add r0.w, r1.x, -r0.z // r0.w = depth-uv.z
0176: cmp r10.xy, r0.w, r0, r10 // st = (uv.z<=depth) ? uv : st;
0177: add r2.w, r3.x, -r2.z // r0.w = depth-uv.z
0178: cmp r10.xy, r2.w, r2, r10 // st = (uv.z<=depth) ? uv : st;
0179: add r4.w, r5.x, -r4.z // r0.w = depth-uv.z
0180: cmp r10.xy, r4.w, r4, r10 // st = (uv.z<=depth) ? uv : st;
0181: add r6.w, r7.x, -r6.z // r0.w = depth-uv.z
0182: cmp r10.xy, r6.w, r6, r10 // st = (uv.z<=depth) ? uv : st;
0183: add r8.w, r9.x, -r8.z // r0.w = depth-uv.z
0184: cmp r10.xy, r8.w, r8, r10 // st = (uv.z<=depth) ? uv : st;
0185:
0186: mul r11.xyz, r11, c2.y
0187: add r0.xyz, r0, r11
0188: add r2.xyz, r2, r11
0189: add r4.xyz, r4, r11
0190: add r6.xyz, r6, r11
0191: add r8.xyz, r8, r11
0192:
0193: texld r1, r0, s0
0194: texld r3, r2, s0
0195: texld r5, r4, s0
0196: texld r7, r6, s0
0197: texld r9, r8, s0
0198:
0199: add r0.w, r1.x, -r0.z // r0.w = depth-uv.z
0200: cmp r10.xy, r0.w, r0, r10 // st = (uv.z<=depth) ? uv : st;
0201: add r2.w, r3.x, -r2.z // r0.w = depth-uv.z
0202: cmp r10.xy, r2.w, r2, r10 // st = (uv.z<=depth) ? uv : st;
0203: add r4.w, r5.x, -r4.z // r0.w = depth-uv.z
0204: cmp r10.xy, r4.w, r4, r10 // st = (uv.z<=depth) ? uv : st;
0205: add r6.w, r7.x, -r6.z // r0.w = depth-uv.z
0206: cmp r10.xy, r6.w, r6, r10 // st = (uv.z<=depth) ? uv : st;
0207: add r8.w, r9.x, -r8.z // r0.w = depth-uv.z
0208: cmp r10.xy, r8.w, r8, r10 // st = (uv.z<=depth) ? uv : st;
0209:
0210: // アルファ成分をST値から求める
0211: add r0.w, c2.w, -r10.x
0212: add r1.w, r1.w, -r1.w // 定数レジスタ2つを引数にできないので0を作る
0213: cmp_pp r11.w, r0.w, c1.y, r1.w // r11.w = O.w = (st.x<=100000-1) ? 1 : 0;
0214:
0215: texld r0, r10, s1 // Color
0216: texld r1, r10, s2 // Normal
0217:
0218: mad r1.xyz, c1.x, r1, -c1.y // n=2*NormalMap-1
0219: dp3 r1.w, r1, c0 // r1.w = NL
0220: cmp r1.w, r1.w, r1.w, c1.z // r1.w = max(0,NL)
0221: add r1.w, r1.w, c0.w // r1.w = max(0,NL) + amb
0222: mul r11.xyz, r0, r1.w // r11 = O.xyz = color*(max(0,NL) + amb)
0223:
0224: mov oC0, r11
0225: };
今回のプログラムはHLSLでは10枚のレイヤーを使うプログラムがコンパイルできなかったので、手でアセンブルしました。
奥のレイヤーから深度マップの値がそのレイヤーの深度よりも前にあるか比較しながらテクスチャ座標を検索しました。
ちなみにテクスチャ座標の初期値にほぼありえない大きな値100000を設定しておいて、
最終的にこの値が変化していないかどうかで視線がモデルを貫いているかどうかチェックします。
値が変化していないときは、アルファ成分に0を入れて、線形補間で透明にしています。
今回苦労したのは、順序従属テクスチャでした。
順序従属テクスチャは、テクスチャ座標に一時レジスタr#を使うときの注意で、
texld の出力に使うレジスタを別の texld で使うような状況は、
3つの texld までしか使えないというやつです。
一時レジスタr#は12個しかないので(それでもps.1.1の6倍だ!)、
多くのテクスチャを読み込むときにはどうしても前に使ったレジスタを使い回さざる終えなくなります。
そうすると順序従属テクスチャの制限に引っかっりやすくなります。
この部分は、あまりやりたくないレジスタの組み合わせのパズルの悪夢が残っていますが、がんばってアセンブルしてパフォーマンスをあげましょう。
ちなみに、この制限は、D3DPS20CAPSのD3DPS20CAPS_NODEPENDENTREADLIMIT がたっていれば関係ありません。
おそらくGeForce FX がそうなので、それまで待つのもひとつの手です。
今回は、5個のtexldを同時にして、10個の一時レジスタを使うのを2回おこない、後は法線マップやデカールの読み込みにもう一段の順序従属テクスチャ読み込みを使っています。
あと、最後のほうの部分は、ピクセル単位のランバート拡散なので、難しくないでしょう。
それ以外の設定は、各ポリゴンを6面対のモデルのローカル座標系に変換する部分が
それぞれのテクスチャに応じて違います。
具体的には、それぞれのポリゴンを、辺の長さの半分だけ動かした後に、
90度だけ適当な方向に回せばよいです。
この方向は、テクスチャを作ったときのビュー行列から求まります。
あと、前のプログラムでは、テクスチャ座標を少しはみ出して取っていたのですが、
今回は、ポリゴンとテクスチャ座標をぴったりとあわせてレンダリングします。
それ以外には、ライトの方向をモデルのローカル座標系で渡すのを忘れないようにしましょう。
main.cpp
0462: // 座標変換
0463: switch(i){
0464: case 0:
0465: D3DXMatrixRotationY ( &m,+0.0f*D3DX_PI );
0466: break;
0467: case 1:
0468: D3DXMatrixRotationY ( &m,+1.0f*D3DX_PI );
0469: break;
0470: case 2:
0471: D3DXMatrixRotationY ( &m,+0.5f*D3DX_PI );
0472: break;
0473: case 3:
0474: D3DXMatrixRotationY ( &m,-0.5f*D3DX_PI );
0475: break;
0476: case 4:
0477: D3DXMatrixRotationX ( &m,-0.5f*D3DX_PI );
0478: break;
0479: case 5:
0480: D3DXMatrixRotationX ( &m,+0.5f*D3DX_PI );
0481: break;
0482: }
0483: D3DXMatrixTranslation ( &mL, 0.0f, 0.0f, -1.0 );
0484: mL = mL * m;
0485: m = mL * m_mWorld * m_mView * m_mProj;
0486: m_pEffect->SetMatrix( m_hmWVP, &m );
思った以上に高速にレンダリングできますね。実は実用的なのかもしれません。
LOD の1つの手法として確立されるのではないでしょうか。
それにしても、このプログラムを GeForce FX で動かして見たいですね。
{kind=link}